Data and Programs for the Paper
‘Tempo-Adjusted Period Parity Progression
Measures, Fertility Postponement and
Completed Cohort Fertility’, Demographic
Research 6(6), 91-144
Hans-Peter Kohler*
José Antonio Ortega†
1 March 2002
|
Abstract
In Kohler and Ortega (2002a) [online available at Demographic Research, Volume
6, Article 6], we introduce a new set of tempo-adjusted period parity progression
measures in order to account for two distinct implications caused by delays in
childbearing: tempo distortions imply an underestimation of the quantum of
fertility in observed period data, and the fertility aging effect reduces higher
parity births because the respective exposure is shifted to older ages where
the probability of having another child is quite low. Our measures remove
the former distortion and provide means to assess the latter aging effect. The
measures therefore provide an unified toolkit of fertility measures that (a)
facilitate the description and analysis of past period fertility trends in terms of
synthetic cohort measures, and (b) allow the projection of the timing, level and
distribution of cohort fertility conditional on a postponement scenario. Due to
their explicit relation to cohort behavior, these measures extend and improve
the existing adjustment of the total fertility rate. We apply these methods to
Sweden during 1970-1999. On this web page we provide the data and Splus
programs to replicate the analyses in Kohler and Ortega (2002a). Moreover, we
provide additional details about the estimation of the fitted intensity schedules
and the calculation of the parity progression ratios with continued fertility
postponement.
|
Contents
1 Introduction
Despite the widespread agreement about relevance of tempo distortions, there remains a
substantial controversy about the appropriate way of measuring and adjusting for these
effects. Bongaarts and Feeney (1998, henceforth BF) have recently proposed an adjusted
total fertility rate that measures total fertility rate that would have been observed in a
calendar year if there had been no change in the tempo of fertility during this
year. Kohler and Philipov (2001) have extended this adjustment to include also
variance effects, i.e., changes in the shape of the fertility schedule in addition to
shifts in the mean age. Alternative models for adjusting the TFR have also been
proposed (e.g., Brass 1990; Le Bras 1997), and virtually all of the above approaches are
strongly influenced by the seminal work of Norman Ryder (Ryder 1964, 1983;
see also the review of the literature on period fertility measures in Ortega and
Kohler 2002a). In addition to the debate about the appropriate adjustment for tempo
distortions, there is also a controversy about the relation between tempo-adjusted
fertility measures and cohort fertility. For instance, while the adjusted TFR in the
Bongaarts-Feeney and Kohler-Philipov analyses provides an improved indicator of
period fertility (or quantum), it cannot be used to infer the completed fertility
of the current cohorts of women. This limitation is due to the fact that the
completed cohort fertility depends on the future paths of fertility quantum and
tempo. It can only be properly projected with appropriate assumptions about
both aspects of future fertility trends. Moreover, investigating these implications
of future quantum and tempo changes on cohort fertility requires an explicit
consideration of the fact that only women who are currently at parity zero, one, two,
etc., are exposed to giving birth to their first, second, third, etc., child. This
sequencing of births is not explicitly considered in the calculation of the adjusted
TFR or the standard TFR. In many circumstances, therefore, these measures
provide little or even erroneous information about the parity distribution and the
completed fertility of cohorts (Kim and Schoen 2000; Ortega and Kohler 2002b; van
Imhoff 2001).
In order to overcome this limitation, we develop in Kohler and Ortega (2002a) [online
available at Demographic Research, Volume 6, Article 6] tempo-adjusted period parity
progression measures. These tempo-adjusted parity progression measures provide a new
and unified ‘tool-kit’ that can be used for two related purposes. First, they remove tempo
distortions and parity composition effects from the observed period fertility
pattern and therefore provide an improved indicator of the period quantum of
fertility. In particular, our tempo-adjusted period parity progression measures
suggest a natural synthetic-cohort measure of period fertility and quantum,
denoted period fertility index, that is equal to the total fertility of women who
experience the tempo-adjusted period childbearing intensities (or adjusted age-specific
parity progression probabilities) during their life-course. Second, our measures
allow a demographically correct and consistent projection of the level, timing
and distribution of the completed fertility of cohorts, who have not finished
childbearing, conditional on the future paths of quantum and tempo. We derive these
assumptions about future quantum and tempo from observed period fertility
patterns. Our methods therefore provide an important input for population
projections, and future analyses can combine these methods with stochastic forecasting
models that explicitly consider the uncertainty about the future development
of quantum and tempo. Moreover, the close relation between period fertility
measurement and cohort projection reduce the traditional distinction between
‘cohort’ and ‘period’ approaches to fertility (e.g., Ní Bhrolcháin 1992): our methods
provide proper period measures of fertility that can be combined with projection
scenarios in order to assess the cohort fertility that results from period fertility
patterns.
In addition, the investigation of fertility aging in our analyses is based on the comparison
of two benchmark scenarios for the pace of fertility postponement during the life-course of
a cohort: (a) a postponement stops scenario in which we calculate the parity
progression measures assuming that the postponement comes to a halt after the
reference year, i.e., assuming that there is no further delay of childbearing after the
year for which the period PPRs are calculated (of specific importance in this
context is the index of completed fertility in the postponement stops scenario,
which is also denoted as period fertility index); (b) we contrast these calculations
with a postponement continues scenario in which we assume that the tempo
change (and also any changes in the variance of the fertility schedule) observed in
a reference year prevails over the life-course of a cohort. This postponement
continues scenario thus allows us to calculate cohort fertility under the assumption
that a cohort experiences a level of fertility and pace of fertility postponement
that equals the level of fertility and change in the tempo of fertility observed
in a reference year. In this approach we therefore include the postponement
of fertility in the notion of synthetic cohorts: we derive fertility measures that
reflect the timing, level and distribution of fertility in hypothetical cohorts that
experience the fertility pattern observed in a given calendar year, where the term
‘fertility pattern’ encompasses the level, tempo and tempo change in a calendar
year.
On this web page we provide the data and Splus programs to replicate the analyses in
Kohler and Ortega (2002a, henceforth KO). Moreover, we provide additional
details about the calculation of tempo-adjusted parity progression ratios and their
application to the measurement of period fertility and the projection of cohort
fertility.
All data and program files mentioned below (including the present html document
‘ko-ppr-programs.html’) are also available in a single zip file.
The data and Splus programs provided below are subject to our disclaimer.
This page is also available as a ko-ppr-programs.pdf, which is preferable if you intend to
print archive the file.
2 Updates of Data and Programs
- March 1, 2001: preliminary version online
- March 1, 2002: publication of Kohler and Ortega (2002a) in Demographic
Research and major revision of programs for the calculation of tempo-adjusted
parity progression measures
3 Data for Sweden 1970-1999
The data required for the analysis include the births by age and parity in a
calendar year and a measure of the person years lived by women who are ‘at
risk’ of giving birth to a first, second, third, etc., child. The former information
is identical to the data requirements for the adjustment of the total fertility
rate. The latter information is more specific. For instance, the exposure can be
estimated by the mid-year female population by age and parity. In countries with
population registers it can be obtained from the exact counts of the person-years
lived by age and parity during a calendar year. The primary advantage of these
additional data is that they allow us to relate births of a given parity to the women
who are at risk of giving birth to this parity, i.e., we can base our analyses on
occurrence-exposure rates or fertility intensities. These fertility intensities reflect the
‘hazard’ of experiencing a next birth at a given age for women who are parity j in a
calendar period.
The data the analyses in KO are obtained and updated from Andersson (1999) and include
births by parity and age during 1970-1999 and estimates of the corresponding
person-years of exposure by age and parity in all calendar years from 1970-1999 (see
also Andersson and Guiping 2001). These data are calculated from files with individual life
stories of all Swedish women. Some observations have been censored, for instance at first
emigrations, twin births, and some further events so the data do not comprise exactly all
births and exposures during this period. Immigrant women are not included in the data
(For a further description of the data see Andersson 1999). Due to the exclusion of the
foreign-born population, the data yield a total fertility rate and related fertility
measures that are slightly below published statistics for the Swedish resident
population.
The data are available in tab-delimited ASCII files below. All data are in period-cohort
format, that is, they trace real cohorts over time and pertain to parallelograms with
vertical sides in the Lexis diagram. Age pertains to the age at the beginning of the period,
and cohorts age by one year during the calendar year.
- standard age-specific fertility rates by birth order (also denoted as “incidence
rates”): birth order 1, birth order 2, birth order 3, birth order 4.
- age-specific childbearing intensities (denoted mj(a, t) in KO): birth order 1,
birth order 2, birth order 3; in our analyses, we combine births of order 4
and higher and treat the population of parity 3 or higher as the respective
population “at risk”. The childbearing intensities for this open-ended category
are calculated by our programs.
- parity distribution at mid-period: parity 0, parity 1, parity 2, parity 3 and
higher.
4 Empirical Implementation
In the following we briefly discuss the empirical implementation and estimation of the
tempo-adjusted period parity progression measures proposed in this paper. S-plus
programs to perform these calculations are provided below.
Once the childbearing intensities, age-specific fertility rates and parity-distribution have
been obtained (see previous section), the calculation of tempo-adjusted parity
progression measures proceeds in two steps. First, we estimate mean- and variance
changes in the schedules of period childbearing intensities for each calendar
year and compute the adjusted childbearing intensities. Second, we use these
tempo-adjusted childbearing intensities to calculate fertility measures for the synthetic
cohort.
The first step requires that we calculate the mean and variances of the adjusted intensity
schedules in all calendar years. In the presence of variance effects, the respective
estimation is somewhat more complicated than in the standard BF adjustment of the
total fertility rate because variance effects distort the shape of the intensity schedule (see
Kohler and Philipov 2001 for a detailed discussion of the distortions in the observed
fertility pattern that are caused by variance effects). The shape of the observed intensity
schedule therefore differs from the adjusted intensity schedule at parity j whenever
variance effects are present. In order to properly estimate the adjusted intensity schedule
along with its mean- and variance changes we therefore implement the following iterative
procedure:
- We estimate the mean age and variance of all period intensity schedules for
parities j = 1, ...J, where J is the highest parity (the Splus functions below
assume that J = 3 (i.e., births of order 4), and they can accommodate
situations where J is an open-ended category that includes births of order 4
and higher. Since childbearing intensities for higher parities tend to be quite
variable at young ages, it is advisable to restrict the intensities to ‘relevant’
ages (for instance, in our analyses for Sweden we have dropped the childbearing
intensities for third and fourth births below the ages of 20 and 21, since third
and fourth birth fertility below these ages does not contribute importantly to
the overall period and cohort fertility).
- We estimate the mean and variance changes in the observed childbearing
intensities. In order to achieve a robust estimation, we use IRW methods based
on state-space smoothing (García-Ferrer et al. 2001; Young 1994), where the ratio
of the variance of the noise in the mean age series to the variance in the
derivative (the so-called Noise Variance Ratio, NV R) is fixed.
This IRW model is specified as follows. The measurement equation states that the
observed series (in our case the mean age and standard deviation of the period
intensity schedule at parity j) is the sum of an unobserved trend component, Tt,
and a noise component with variance 
 2:
2:
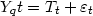 | (1) |
The transition equations state that the trend component changes in each period
through the addition of a slope component (the derivative estimate) which changes
overtime through the addition of a noise component 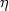 t with variance 2:
The system depends on a single parameter, the noise variance ratio NV R = 2/2,
that reflects the variance of noise in the observed series Y t relative to the noise
in the underlying trend component Tt. The extraction of the trend and
slope components implies the forward application of the Kalman filter
algorithm and the backward application of Fixed Interval Smoothing. We
implement this smoothing technique because of its desirable spectral properties:
there is a relationship between the NV R and the cut-off frequency of the
filter.
t with variance 2:
The system depends on a single parameter, the noise variance ratio NV R = 2/2,
that reflects the variance of noise in the observed series Y t relative to the noise
in the underlying trend component Tt. The extraction of the trend and
slope components implies the forward application of the Kalman filter
algorithm and the backward application of Fixed Interval Smoothing. We
implement this smoothing technique because of its desirable spectral properties:
there is a relationship between the NV R and the cut-off frequency of the
filter.
- We estimate the adjusted intensity schedule at parity j on the basis of the observed
childbearing intensities and the annual mean- and variance changes obtained in the
previous step.
- We re-estimate the mean- and variance change,
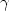 j(t) and
j(t) and 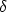 j(t), for all calendar
years based on the adjusted intensity schedules obtained in the previous
step.
j(t), for all calendar
years based on the adjusted intensity schedules obtained in the previous
step.
- We return to step 3 and re-estimate the adjusted intensity schedule based on the
new values of j(t) and j(t). The iteration stops once the estimates for the mean-
and variance changes converge.
Once the adjusted intensity schedules have been estimated for all calendar years, the
tempo-adjusted parity progression measures proposed in this paper can be calculated by
using discrete-time versions of the results in KP.
Once the data have been read into a specific KO data object (see Section 6.2 below), the
analyses (including the graphics) of the Swedish fertility patterns in KO and Kohler and
Ortega (2002b) is replicated by the following Splus commands that are discussed in more
detail below:
## calculate adjusted TFR
se.data <- ko.add.tfr.adjustment(se.data)
## estimate mean and variance changes in KO
se.data <- ko.ppr.add.fitted(se.data)
## calculate tempo-adjusted period parity progression measures
se.ppr.comparison <- ko.ppr.comparison(se.data)
## cohort summary for nfx cohort data
se.cohort.summary <-
ko.calc.cohort.summary(se.long.data,
first.cohort = 1930,
use.initial.par.dist = T)
## complete fertility of cohorts who have not completed childbearing in
## the years 1975,1999
se.complete.fert.1975 <-
ko.ppr.complete.fert.3.scenarios(se.data,1975,
par.dist =
se.cohort.summary$par.dist[,se.cohort.summary$years==1975,],
cum.nfx =
se.cohort.summary$cum.nfx[,se.cohort.summary$years==1975,],
cum.mab =
se.cohort.summary$cum.mab[,se.cohort.summary$years==1975,]
)
se.complete.fert.1999 <-
ko.ppr.complete.fert.3.scenarios(se.data,1999,
par.dist =
se.cohort.summary$par.dist[,se.cohort.summary$years==1999,],
cum.nfx =
se.cohort.summary$cum.nfx[,se.cohort.summary$years==1999,],
cum.mab =
se.cohort.summary$cum.mab[,se.cohort.summary$years==1999,]
)
## Create graphs with various fertility indicators
## (this step requires some additional definitions, see
## Section 7)
source("ko-ppr-tokyo-figures.ssc")
|
5 Splus Programs and Scripts
In the following, we discuss the above implementation of tempo-adjusted parity
progression measures in some additional detail. In particular, the estimation of
tempo- and variance changes in the parity-specific schedules of childbearing
intensities and calculation of parity progression ratios in are implemented via several
Splus functions that need to be defined by sourcing the following script files
(i.e., by executing the Splus command source(`filename.ssc') at the Splus
command prompt). The functions defined by these script files are further explained
below.
6 A Quick Tour: Replicating the Analyses in KO
The following commands replicates the analyses in our paper. All these commands are
also provided in the script file ko-ppr-quicktour.ssc.
6.1 Prepare the analyses
## if necessary, delete all existing objects in the Splus working
## directory
remove(objects(pattern = "*"))
## source the above script files to define Splus functions for the
## analyses
## load KO smoother
source("ko-smoother.ssc", synch = T)
## load auxiliary functions
source("ko-auxfunctions.ssc", synch = T)
## load functions for KO-PPR analyses
source("ko-ppr-functions.ssc", synch = T)
## reset various options for ko-ppr analyses
## that are specified (and can be changed) in
## ko.ppr.control
ko.ppr.reset()
|
6.2 Read Swedish fertility data
The first step is to create a KO data object that contains all fertility data required for
the calculation of tempo-adjusted parity progression measures in a list element data. In
the Swedish case, this KO data object will be called se.data. When used as an
argument in functions, we will refer to the KO data object by its generic name
all.data.
The following lines read the Swedish data from the ASCII files (see above) into the KO
data object using a function ko.add.data. The KO data object needs to be have the
exact format (especially name of the list-elements) assigned by the function ko.add.data
because the subsequent calculations will extract information from that list using the
names and/or structure defined below. The syntax of this function and default value of its
arguments are given by
-
- ko.add.data(years, age, max.order = 4, period.age.data = !period.cohort.data,
period.cohort.data = !period.age.data, last.rates.not.oerates = T, mat =
NULL, nfx, par.dist = NULL)
and the specific implementation to read the data for Sweden is as follows:
se.data <-
ko.add.data(years = 1970:1999,
age = 15:44,
max.order = 4,
period.cohort.data = T,
last.rates.not.oerates = T,
mat = list(
order.1 = ko.matread("se-mat-1.txt",
data.years=1961:1999,keep.years=1970:1999,set.rows=NULL,
set.na.to.zero=T),
order.2 = ko.matread("se-mat-2.txt",
data.years=1961:1999,keep.years=1970:1999,set.rows=1:2,
set.na.to.zero=T),
order.3 = ko.matread("se-mat-3.txt",
data.years=1961:1999,keep.years=1970:1999,set.rows=1:5,
set.na.to.zero=T)
),
nfx = list(
order.1 = ko.matread("se-nfx-1.txt",
data.years=1961:1999,keep.years=1970:1999,set.rows=NULL,
set.na.to.zero=T),
order.2 = ko.matread("se-nfx-2.txt",
data.years=1961:1999,keep.years=1970:1999,set.rows=1:2,
set.na.to.zero=T),
order.3 = ko.matread("se-nfx-3.txt",
data.years=1961:1999,keep.years=1970:1999,set.rows=1:5,
set.na.to.zero=T),
order.4 = ko.matread("se-nfx-4plus.txt",
data.years=1961:1999,keep.years=1970:1999,set.rows=1:8,
set.na.to.zero=T)),
par.dist = list(
parity.0 = ko.matread("se-pardist-0.txt",
data.years=1961:1999,keep.years=1970:1999,set.rows=NULL,
set.na.to.zero=T),
parity.1 = ko.matread("se-pardist-1.txt",
data.years=1961:1999,keep.years=1970:1999,set.rows=NULL,
set.na.to.zero=T),
parity.2 = ko.matread("se-pardist-2.txt",
data.years=1961:1999,keep.years=1970:1999,set.rows=NULL,
set.na.to.zero=T),
parity.3 = ko.matread("se-pardist-3plus.txt",
data.years=1961:1999,keep.years=1970:1999,set.rows=NULL,
set.na.to.zero=T)
)
)
|
The first arguments of the function ko.add.data provide a description of the data used in
the analyses, as for instance the years (years = 1970:1999) and age range (age =
15:44), the format of the data (either period.cohort.data = T or period.age.data =
T), and an indicator of whether the last category pertain to an open-ended category with
births of order 4 and higher (as for Sweden, where we set last.rates.not.oerates =
T).
The next arguments of the function ko.add.data provide the childbearing intensities
(mat), age-specific fertility rates (nfx) and the parity distribution (par.dist) as lists,
where the list elements are the respective parity specific information in the form of
matrices. In order to read the data files (see above) and provide them in these list
elements, we utilize an auxiliary function ko.matread with the arguments (and default
values) given by
-
- ko.matread(read.what, keep.rows = NULL, keep.cols = NULL, data.years =
NULL, keep.years = NULL, data.age = NULL, keep.age = NULL, set.rows =
NULL, set.to.value = 0, set.na.to.zero = F)
This auxiliary function allows to extract the years 1970-1999 from the data file containing
the years 1961-99, and it allows to set the data to zero in specified rows. For instance, in
the above application to Sweden we set the childbearing intensities, incidence rates and
parity distribution to zero for ages up to 16 years (birth order 2), 19 years (birth order 3)
and 22 years (birth order 4+).
After the function ko.add.data is performed, the KO data object se.data contains a
list-element data that contains the childbearing intensities (mat), age-specific fertility
rates (nfx) and the parity distribution (par.dist) that are subsequently used in the
analyses.
The following lines calculate some summary information for the childbearing intensities
and incidence rates (age-specific fertility rates) in each calendar year:
## Print summary of nfx
print(ko.asr.summary(se.data))
print(ko.asr.summary(se.data, what = "mat"))
|
The KO data object se.data contains the primary data used in our analyses. In some
cases, however, we need to reconstruct cohort fertility and for these purposes it is
useful--albeit not essential--to utilize the additional information contained in Anderson’s
data. In particular, the data start in 1961 (with ages up to 35) and the data therefore
allow to reconstruct the complete cohort fertility experience of cohorts born after 1945,
i.e., of cohorts who attained age 15 in 1960 or later. In order to utilize these additional
data for the period 1961-69, which have not been included when we specified the
object se.data above, we additionally define a new object se.long.data as
follows:
se.long.data <-
ko.add.data(years = 1961:1999,
age = 15:44,
max.order = 4,
period.cohort.data = T,
last.rates.not.oerates = T,
mat = list(
order.1 = ko.matread("se-mat-1.txt",
set.rows=NULL,
set.na.to.zero=T),
order.2 = ko.matread("se-mat-2.txt",
set.rows=1:2,
set.na.to.zero=T),
order.3 = ko.matread("se-mat-3.txt",
set.rows=1:5,
set.na.to.zero=T)
),
nfx = list(
order.1 = ko.matread("se-nfx-1.txt",
set.rows=NULL,
set.na.to.zero=T),
order.2 = ko.matread("se-nfx-2.txt",
set.rows=1:2,
set.na.to.zero=T),
order.3 = ko.matread("se-nfx-3.txt",
set.rows=1:5,
set.na.to.zero=T),
order.4 = ko.matread("se-nfx-4plus.txt",
set.rows=1:8,
set.na.to.zero=T)),
par.dist = list(
parity.0 = ko.matread("se-pardist-0.txt",
set.rows=NULL,
set.na.to.zero=T),
parity.1 = ko.matread("se-pardist-1.txt",
set.rows=NULL,
set.na.to.zero=T),
parity.2 = ko.matread("se-pardist-2.txt",
set.rows=NULL,
set.na.to.zero=T),
parity.3 = ko.matread("se-pardist-3plus.txt",
set.rows=NULL,
set.na.to.zero=T)
)
)
|
6.3 Calculate BF-adjusted total fertility rate
The next function ko.ppr.tfr.adjustment, which takes the syntax
-
- ko.ppr.tfr.adjustment(all.data)
where all.data is the generic name for the KO data object generated in the previous
section. The function ko.ppr.tfr.adjustment adds a list element tfr.adjustment to
the KO data object that contains the BF-adjusted total fertility rate for Sweden (along
with estimates of r). The only difference in this calculation to Bongaarts and Feeney’s
original implementation is that we use the IRW smoothing methods, defined in
ko-smoother and described in Section 4 above, to estimate the annual changes in the
order-specific mean ages at birth (recall that the mean ages in the BF adjustment are
calculated from standard age-specific fertility rates, or incidence rates, instead of
childbearing intensities).
In the Swedish example, the syntax to perform the BF-adjustment of the TFR
is
## calculate adjusted TFR
se.data <- ko.add.tfr.adjustment(se.data)
|
6.4 Estimation of mean- and variance changes in KO
The function ko.ppr.add.fitted performs the estimation of the parity-specific mean and
variance changes of the childbearing intensity schedules, denoted j(t) and j(t), and
the level-effect qj(t) for all time periods t. The syntax of this function is given
by
-
- ko.ppr.add.fitted(all.data, calc.for.years)
where all.data is the function argument that takes the KO data object defined in Section
6.2 (which is called se.data in our Swedish example). The optional additional
argument, calc.for.years provide a possibility to restrict the calculations to a
subset of years (the default is to perform the analyses for all years include in
all.data.
The tempo-adjusted childbearing intensities are not directly calculated by the above
routines, and can be extracted from the KO data object using the following
function:
-
- ko.ppr.predict.adjusted(all.data, b.order, years, years.i)
where all.data is the generic name for the KO data object, and b.order specifies the
birth order for which the tempo-adjusted intensities are calculated. The optional
additional arguments, years and years.i, allow to restrict this calculation to specific
years giving either directly the year (years) or the sequence in the range of years
(years.i).
In the Swedish case, the estimation of mean- and variance changes in the schedules of
childbearing intensities is implemented as follows:
## application of estimation
se.data <- ko.ppr.add.fitted(se.data)
## calculate the tempo-adjusted childbearing intensities
## for first births
## (Note: this object is not required for subsequent analyses
## and is not used as input by other functions)
se.adjusted.intensities <-
ko.ppr.predict.adjusted(se.data, b.order = 1)
|
6.5 Estimation of tempo-adjusted period parity measures
The first application of our measures is the description of period fertility patterns based
on fertility indicators for a synthetic cohort synthetic cohort that experiences the period
fertility pattern (level, tempo and potentially tempo-change) during its life-course. Most
analyses using tempo-adjusted parity progression measures will generally be based on the
following fertility indicators:
- period life-time birth probability of one, two,... children: this measure reflects
the probability that a woman in the synthetic cohort gives birth to at least
one, two,... children conditional on (a) the parity-specific level of fertility
in the reference year after removing tempo distortions and (b) the assumed
postponement pattern during the life-course of the synthetic cohort.
- period parity progression ratios (period PPRs): these period PPRs reflect the
probability of progressing from parity j to parity j + 1 conditional on the
level of fertility observed in the reference year and the assumed postponement
pattern during the life-course of the synthetic cohort.
- index of completed fertility: this index reflects the expected number of children
for women in the synthetic cohort conditional on the level of fertility observed
in the reference year and the assumed postponement pattern during the
life-course of the synthetic cohort.
- period fertility index: this is a special case of the above index of completed
fertility calculated under the assumption that there is no further change in
the timing of fertility during the life-course of the synthetic cohort; the period
fertility index therefore assumes that women in the synthetic cohort are subject
to the tempo-adjusted period childbearing intensities (for a detailed discussion
of the period fertility index and its usefulness as a period fertility measure, see
also Kohler and Ortega 2002a; Ortega and Kohler 2002a,b).
These measures (and some related period fertility indicators) are calculated by the
function ko.ppr.comparison that takes the following arguments (along with its default
values)
-
- ko.ppr.comparison(all.data, calc.for.years = NULL, xx.values = seq(15,25,by =
10))
where all.data is the KO data object, calc.for.years is an optional additional argument to
restrict the calculations to a subset of years (the default is to perform the analyses for all
years include in all.data, and xx.values allows to specify the age of the cohort in the
reference year for which the parity progression measures are calculated (the default is to
perform the calculation for cohorts age 15 and 25 years old in the reference year, where
the first cohort is of particular relevance since it is at the beginning of its childbearing
years).
In the Swedish case, the function is implemented as follows:
## calculate period parity progression measures
se.ppr.comparison <- ko.ppr.comparison(se.data)
|
Although it is not necessary for the implementation of the estimation, it is useful for
understanding the calculations that we briefly describe the key functions that are called
by the function ko.ppr.comparison during the calculation of the tempo-adjusted period
parity progression measures.
-
- ko.ppr.p(xx, yy, q.T = 1, mab.T, sdab.T, gamma = 0, delta = 0, period.T
= 0, phi.points, postponement.continues = T, calc.from.observed = F): this
function calculates the probability that a women the synthetic cohort, who is
age xx in the reference year and at parity j at some age yy, experiences a birth
of order j + 1. The additional arguments specify the mean age and variance
of the adjusted intensity schedule in the reference year (mab.T and sdab.T),
gamma and delta specify the mean- and variance changes estimated in the
reference year.
The arguments phi.points provide a discrete-time approximation of the
tempo-adjusted childbearing intensities at parity j. In particular, we calculate
the adjusted childbearing intensities at “mid-age” (e.g., at ages 15.5, 16.5, 17.5,
..., 44.5 in the Swedish case), using the estimated mean and variance change in
the reference year (this calculation of the adjusted childbearing intensities is
performed via the function ko.ppr.predict.adjusted described above). For
ages between these “mid-ages”, we use a linear interpolation.
The remaining arguments specify whether the calculations are based on
the postponement stops scenario (postponement.continues = F) or the
postponement continues scenario (postponement.continues = T). If the
postponement continues scenario is chosen, the cohort experiences the annual
mean and variance changes given by the arguments gamma and delta
during its life-course. Moreover, the option calc.from.observed = T allows
to specify that the calculations are based on the observed instead of the
tempo-adjusted childbearing intensities (this option can only be combined with
the postponement stops scenario).
Based on the above information, the function ko.ppr.p performs the integral
where mjs(a, T + a - x) are the childbearing intensities by women in the cohort
under consideration, and Rjs(y, T + (y - x)) is the tempo change that is
accumulated between the reference year T and the period T + (y - x) when the
women is at age y and exposed to a order j + 1birth.
-
- ko.ppr.p.from.fitted(xx, yy, ii = 0, period.T = 0, all.data, postponement.continues =
T, calc.from.observed = F, add.postponement.years = 0, overwrite.last.rates =
NULL): helper function that calls ko.ppr.p for a given birth order ii + 1, using the
information stored in the KO data object all.data.
-
- ko.ppr.DF(xx, ii, period.T, all.data, postponement.continues = T, calc.from.observed =
F, add.postponement.years = 0): iteratively calculates the parity distribution, birth
probability and related information for a synthetic cohort that is age xx and parity
ii in the reference year, using the information stored in the KO data object
all.data.
-
- There are also some additional helper functions that iterate through all calendar
years and parities for the calculations; the primary calculations for the
parity progression measures, however, are performed by the functions listed
above.
6.6 Completion of cohort fertility
The second application of our period parity progression measures is the completion of
cohort fertility. This completion is possible because the measures calculated in the
previous section provide conditional projections for the period-T cohorts at all ages and
parities. This allows us to take the parity distribution observed in the reference year T as
the starting point for the calculation. We then use period parity progression measures to
fill in the ‘missing’ part of a cohort’s childbearing pattern conditional on future trends in
the tempo and parity-specific level of fertility. In the cohort completions that we
present in KO, the projection of future fertility is based on the parity-specific
level of fertility qj(T) in the reference year and the parity-specific postponement
pattern given by js and js for all parities j = 0, .... The completed fertility
of birth cohorts then follows via a weighted average of the conditional total
fertility indexes across all parities in the reference year T, where the weights are
equal to the observed parity distribution of the cohort in the reference year
T.
This calculation is conditional on a specific postponement scenario. Particularly
interesting and appealing for cohort completion, and therefore implemented via the below
functions, are the postponement stops (s = 0, s = 0) and the postponement continues
(s = T , s = T ) scenarios.
While the completed cohort fertility is a centrally important indicator of cohort fertility,
the analysis with our period parity progression measures is not restricted to this measure.
Other cohort fertility measures, such as the final parity distribution or the mean age at
birth (overall or at some specific birth order), can also be obtained by taking
corresponding weighted averages. For instance, the cohort mean age at birth of order j
can be calculated via a weighted average between the mean age of women at order-j
births prior to the year T and the order-specific mean age at order-j births that are
projected to occur in the future.
The completion of cohort fertility is implemented via two functions that perform (a) the
calculation of the cohort parity distribution at the end of the reference year and (b) the
projection of cohort fertility via a weighted average of the conditional total fertility
indexes across all parities in the reference year T, where the weights are equal to the
observed parity distribution of the cohort in the reference year T. The respective
functions are as follows:
-
- ko.calc.cohort.summary(all.data, first.cohort = NULL, use.initial.par.dist=F):
this function calculates the completed fertility and final childlessness (for
cohorts that have completed childbearing) and the cumulated fertility of
cohorts still in childbearing years. For these cohorts, the function also
calculates the order-specific mean age at birth for births that have so far
occurred to the cohort, and it calculates the parity distribution on Dec 31 of
each year. The function ko.calc.cohort.summary takes the KO data element
as first argument, and the optional additional arguments specify the first cohort
for which the calculations are performed first.cohort and whether the parity
distribution supplied in the KO data object should be used to “fill in” parts of
a cohorts fertility history that are not available in the nfx-matrices supplied
in the KO data matrix.
-
- ko.ppr.complete.fert.3.scenarios(all.data, period.T, age.mid = NULL,
par.dist = NULL, cum.nfx = NULL, cum.mab = NULL): calculates the cohort
projection under the postponement stops and postponement continues scenario
as well as based on the observed childbearing intensities. The arguments are the
KO data object, and several optional arguments that allow to specify mid-age
age.mid, the parity distribution par.dist, the cumulated fertility cum.nfx and
the mean age at birth (prior to reference year) cum.mab.
The information for these optional arguments in
ko.ppr.complete.fert.3.scenarios is calculated from the KO data object
via the above function ko.calc.cohort.summary.
In the Swedish case, the commands to for the completion of cohort fertility are as
follows:
## cohort summary for nfx cohort data
se.cohort.summary <-
ko.calc.cohort.summary(se.long.data,
first.cohort = 1930,
use.initial.par.dist = T)
##complete fertility in the years 1975,1999
se.complete.fert.1975 <-
ko.ppr.complete.fert.3.scenarios(se.data,1975,
par.dist =
se.cohort.summary$par.dist[,se.cohort.summary$years==1975,],
cum.nfx =
se.cohort.summary$cum.nfx[,se.cohort.summary$years==1975,],
cum.mab =
se.cohort.summary$cum.mab[,se.cohort.summary$years==1975,]
)
se.complete.fert.1999 <-
ko.ppr.complete.fert.3.scenarios(se.data,1999,
par.dist =
se.cohort.summary$par.dist[,se.cohort.summary$years==1999,],
cum.nfx =
se.cohort.summary$cum.nfx[,se.cohort.summary$years==1999,],
cum.mab =
se.cohort.summary$cum.mab[,se.cohort.summary$years==1999,]
)
|
7 Output: figures for KO analysis
The following commands draw a variety of figures that are reported in Kohler and
Ortega (2002a) and Kohler and Ortega (2002b).
## make some assignments that allow a flexibly change of
## countries
ko.per.data <- se.data
ko.ppr.data <- se.ppr.comparison
ko.coh.data <- se.cohort.summary
ko.refyrs <- c(1975,1999)
ko.coh.complete <- list(ref.yr.1975 = se.complete.fert.1975,
ref.yr.1999 = se.complete.fert.1999)
## these lines define a set of options that specifies the
## position of legends, etc, for the graphs
ko.p.opt <-
list(
## lifetime birth prob graphs
ltb.key.xpos=c(1970,1970,1970),
ltb.key.ypos=c(.74,.8,.38),
## parity progression rates
ppr.key.xpos=c(1970,1970),
ppr.key.ypos=c(.93,.5),
## adjusted tfr graph
tfr.1.key.xpos = 1970,
tfr.1.key.ypos = .96,
tfr.1.ylim =c(.6,1.1),
tfr.a.key.xpos = 1970,
tfr.a.key.ypos = 2.3,
tfr.a.ylim = c(1.4,2.4),
tfr.comp.1.key.xpos = 1970,
tfr.comp.1.key.ypos = .45,
tfr.comp.a.key.xpos = 1977,
tfr.comp.a.key.ypos = 1,
## projections
proj.complete.age = 44,
proj.cohort.lim =c(1930,1985),
proj.ylim.1 = c(.08,.28),
proj.ylim.2 = c(1.4,2.1),
proj.ctext.ypos = list(c(.27,.25,1.48,1.43),
c(.27,.25,1.48,1.43)),
## mean variance changes
mvc.mablim = list(c(25.5,31.5),c(25.5,30.5),c(25.5,31.5)),
mvc.mab.key.xpos = 1970,
mvc.sdlim = list(c(4.85,5.45),c(4.85,5.45),c(4.6,5.2)),
mvc.gammalim = list(c(-.05,.25),c(-.05,.25),c(-.05,.25)),
mvc.deltalim = list(c(-.005,.01),c(-.005,.01),c(-.005,.001))
)
## this script file reproduces the figures in KO
source("ko-ppr-tokyo-figures.ssc")
|
8 Customization
The script file ko-ppr-functions.ssc defines a object ko.ppr.control that
contains various defaults for parameters used in the calculations that can be
changed by the user (although caution is warranted). The default setting is as
follows:
ko.ppr.control <-
list(
## smoothing for BF calculations
bf.smooth.par.firstbirths = .1,
bf.smooth.reduction.parity = 1,
## smoothing parameters for KO application
ko.smooth.par.firstbirths = .1,
ko.smooth.reduction.parity = 1,
ko.smooth.reduction.variance = 1,
## criteria for iterative fitting
iteratefit.mean.crit = .000001,
iteratefit.max.crit = .00001,
iteratefit.max.iter = 40,
## for PPR calculations
max.age = 70,
age.step = 1
)
|
It is possible to re-set ko.ppr.control to its default values using
References
Andersson, G. (1999). Childbearing trends in Sweden 1961-1995. European Journal
of Population 15(1), 1-24.
Andersson, G. and L. Guiping (2001). Demographic trends in Sweden: Childbearing
developments in 1961-1999, marriage
and divorce developments in 1971-99. Demographic Research [online available at
http://www.demographic-research.org] 5(3), 65-78.
Bongaarts, J. and G. Feeney (1998). On the quantum and tempo of fertility.
Population and Development Review 24(2), 271-291.
Brass, W. (1990). Cohort and time period measure of quantum and fertility:
Concepts and methodology. In H. A. Becker (Ed.), Life Histories and Generations,
Volume 2, pp. 455-476. Utrecht: ISOR, Faculty of Social Sciences, University of
Utrecht.
Garcia-Ferrer, A., J. del Hoyo, P. C. Young, and A. Novales (1993). Recursive
identification, estimation and forecasting of nonstationary economic time series
with applications to GNP international data.
García-Ferrer, A., R. Queralt, and C. Blázquez (2001). A growth cycle
characterisation and forecasting of the Spanish economy: 1970-1998. International
Journal of Forecasting 17, 517-532.
Kim, Y. J. and R. Schoen (2000). On the quantum and tempo of fertility: Limits
to the Bongaarts-Feeney adjustment. Population and Development Review 26(3),
554-559.
Kohler, H.-P. and J. A. Ortega (2002b). Tempo-adjusted period parity progression
measures: Assessing the implications of delayed childbearing for fertility in
Sweden, the Netherlands and Spain. Demographic Research [online available at
http://www.demographic-research.org] 6(7), 145-190.
Kohler, H.-P. and J. A. Ortega (2002a). Tempo-adjusted period parity progression
measures, fertility postponement and completed cohort fertility. Demographic
Research [online available at http://www.demographic-research.org] 6(6), 91-144.
Kohler, H.-P. and D. Philipov (2001). Variance effects in the Bongaarts-Feeney
formula. Demography 38(1), 1-16.
Le Bras, H. (1997). Fertility: The condition of self-perpetuation. Differing trends
in Europe. In M. Gullestad and M. Segalen (Eds.), Family and Kinship in Europe,
pp. 14-32. Pinter Publishers.
Ní Bhrolcháin, M. (1992). Period paramount? A critique of the cohort approach to
fertility. Population and Development Review 18(4), 599-629.
Ortega, J. A. and H.-P. Kohler (2002a). Measuring low fertility: Rethinking
demographic methods. Max Planck Institute for Demographic Research, Rostock,
Germany, Working Paper #2002-001 (available at http://www.demogr.mpg.de).
Ortega, J. A. and H.-P. Kohler (2002b). A new look at period fertility: A
decomposition of the effects of parity distribution, tempo distortions and fertility
on the period TFR. Mimeo, Max Planck Institute for Demographic Research,
Rostock, Germany.
Ryder, N. B. (1964). The process of demographic translation. Demography 1(1),
74-82.
Ryder, N. B. (1983). Cohort and period measures of changing fertility. 2, 737-756.
R. Bulatao and R. D. Lee.
van Imhoff, E. (2001). On the impossibility of inferring cohort fertility measures
from period fertility measures. Demographic Research [online available at http://
www.demographic-research.org] 5(2), 23-64.
Young, P. C. (1994). Time variable parameter and trend estimation in non-stationary
economic time series. Journal of Forecasting 13(2), 179-210.
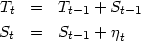
![[ integral w ]
1 - exp - msj(a, T + a- x)da
[ y ]
integral w
= 1 - exp - s m'j(a,T )da , (2)
y-Rj(y,T+(y-x))](ko-ppr-programs2x.gif)